ISSN 1884-0760
GRACE TECHNICAL REPORTS
Shortest Regular Category-Path Queries
Le-Duc TUNG Kento EMOTO Zhenjiang HU
GRACE-TR 2014-03
August 2014
CENTER FOR GLOBAL RESEARCH IN
ADVANCED SOFTWARE SCIENCE AND ENGINEERING
NATIONAL INSTITUTE OF INFORMATICS
2-1-2 HITOTSUBASHI, CHIYODA-KU, TOKYO, JAPAN
Shortest Regular Category-Path Queries
Le-Duc TUNG
#1, Kento EMOTO
∗2, Zhenjiang HU
#$3#The Graduate University for Advanced Studies
Shonan Village, Hayama, Kanagawa 240-0193, Japan 1
[email protected] ∗Kyushu Institute of Technology
680-4 Kawazu, Iizuka, Fukuoka 820-8502, Japan 2[email protected]
$National Institute of Informatics
2-1-2 Hitotsubashi, Chiyoda, Tokyo 101-8430, Japan 3[email protected]
Abstract—A Shortest Regular Category-Path (SRCP) query
is a variant of constrained shortest path queries, in which a candidate path of minimum total length has to visit a number of typed locations in a specific way according to a regular expression over the types (categories) of locations. The SRCP query is general and important, covering many interesting path queries such as trip planning queries, optimal sequenced route queries, optimal route queries with arbitrary order constraints. In this paper, we show that a wide class of the SRCP queries can be reduced to a series of single source shortest path searches on the input graph by using a dynamic programming formulation. As a result, we can freely exploit existing speedup techniques for single source shortest path searches to speedup the SRCP query computation. After that, we progressively engineer an efficient implementation for answering the SRCP query by using two forward and backward optimizations. Our experiments of queries on the full American road network (with over 20 million nodes and nearly 60 million edges) show that our solution is practical and scalable for large, real-world road networks.
I. INTRODUCTION
Consider a tourist who will have a free day to travel Tokyo. A friend of hers will pick her up at her hotel, and they will enjoy a Tokyo tour ending with a dinner at the friend’s home. Their tour is being planned like this: Having a breakfast at a cafeteria (F), then visiting two places, a museum (M) and a zoo (Z) in any order, then having lunch at a traditional Japanese restaurant (R), and then in the afternoon doing one of the following options; visiting a shopping mall (S) and then an electronics store (E) followed by a temple (T), or visiting a temple (T) and then a shopping mall (S) followed by an electronics store (E). In such a tour planning, they want to find a path such that (1) it visits locations of interest in a preferred order and (2) it must be the shortest path in terms of its length. This kind of query is very useful and common in practice.
A bunch of work has recently been devoted to solving various kinds of shortest path queries, where a solution path of minimum total cost must satisfy a certain constraint in terms of node categories. Li et al. [1] introduced a trip planning query to find the shortest path going from a starting location, passing through at least one location from each category in a user-specified set of categories and ending at a destination
location. Rice et al. [2] proposed an exact solution for a similar problem and called it ageneralized traveling salesman path problem. Sharifzadeh et al. [3] addressed a query called optimal sequenced route queryin which a total order over all categories is specified, and the destination is a certain location in the last category. Li et al. [4] discussed a query that allows arbitrary (partial, total or between the two) order constraints between different categories e.g., a gas station must be visited before a restaurant but other locations can be visited in an arbitrary order. Rice et al. [5] considered ageneralized shortest path querythat is similar to the optimal sequenced route query but with a specified destination location.
While each specific class of queries is interesting, none of existing queries can directly deal with queries having multiple options as the one in the first paragraph. Constraints for locations in the morning do not require any order, so we can use a trip planning query [1]. A restaurant must be visited after a museum or a zoo, which is a query with arbitrary order constraints [4]. Two options in the afternoon are two queries with total order constraints [3], but they cannot be expressed by a query with arbitrary order constraints [4] because these options expose the contraint “a temple (T) is prohibited only in between a shopping mall (S) and an electronics store (E)” that cannot be expressed by any partial order.
To remedy such above queries, we propose a more general class of queries, calledshortest regular category-path (SRCP) queries, where path constraints on the node categories are described by a regular category-path expression. The SRCP queries are powerful, covering all the existing queries dis-cussed above as well as their combinations. Recall the tour example above, we can describe it as an SRCP query as a triple:
hh,o,F(MZ|ZM)R(SET|TSE)i
query:
hh,o,F(MZ|ZM)R(SET|TSE)(L|F)+i
Now, the challenge is how to solve the SRCP queries efficiently. One direct idea is to utilize the existing solution proposed by Barret et al. [6] on formal-language-constrained shortest path query, in which shortest paths are constrained by a formal language (including regular expressions) for describing requirements on labels associated with nodes/edges of an input graph. Barret’s algorithm computes a product graph of the input graph and a nondeterministic finite automaton constructed from the regular expression, and reduces the query computation to a point-to-point shortest path search on the product graph. However, two problems remain in this approach. First, the product graph could be very huge, and the algorithm would require searching many (or even all) nodes in the product graph. Second, it would be impractical to utilize existing effective preprocessing techniques (e.g., Contraction Hierarchies [7], Precomputed Cluster Distance [8], etc.) for improving the point-to-point shortest path searches, because we have to generate a product graph for each query and thus the preprocessed product graph cannot be used for another query.
In this paper, we show that a wide practical class of the SRCP queries can be reduced to a series of single source shortest path searches on the input graph by using a dy-namic programming formulation; thus, we can exploit existing speedup techniques for single source shortest path searches freely to obtain efficient implementations for answering the SRCP queries.
Our main contributions are summarized as follows.
• We propose a general mechanism (SRCP queries) for
description of various complex kinds of shortest path queries with path constraints on node categories. It covers the existing queries such as trip planning queries, optimal sequenced route queries, optimal route queries with ar-bitrary order constraints, generalized traveling salesman path problem, and generalized shortest path queries.
• We show that a wide practical class of SRCP queries can beefficiently computed, by reducing an SRCP query to a series of single source shortest path searches, and establishing a dynamic programming formulation for the SRCP query computation. In addition, our approach enables utilization of any fast single source shortest path search (sequential or parallel search) to gain the best performance.
• We progressively engineer an efficient implementation for
answering the SRCP queries by using two forward and backward optimizations. Our experiments of queries on the full American road network (with over 20 million nodes and nearly 60 million edges) show that our solu-tion is practical and scalable for large, real-world road networks.
The rest of this paper is organized as follows. Section II gives a formal definition of the Shortest Regular Category-Path query, and discusses its expressiveness. We first introduce
a basic solution based on dynamic programming for answering the SRCP queries in Sect. III and then we engineer it to get an efficient algorithm in Sect. IV. A set of experiments with large data sets is showed in Sect. V. Section VI discusses some related works and Sect. VII concludes the paper.
II. SHORTESTREGULARCATEGORY-PATHQUERIES
In this section, we formally define the shortest regular category-path (SRCP) queries and the related SRCP problem, and demonstrate the expressiveness of SRCP queries through several typical examples.
A. SRCP Queries
The SRCP query is a special case of the known shortest path query.
Definition II.1. (Graph and Shortest Path) LetG= (V, E, w)
be a weighted digraph, where V is the set of nodes in G,
E ⊆V ×V is the set of edges in G, and w : E → R+ is a function mapping each edge inGto a positive, real-valued weight.
Let Ps,t = hv1, v2, . . . , vqi be any path in G from node
s = v1 ∈ V to node t = vq ∈ V, such that, for 1 ≤ i <
q,(vi, vi+1) ∈ E. Let cost(Ps,t) = P1≤i<qw(vi, vi+1) be the cost ofPs,t. A pathPs,t′ is called ashortest pathfromsto
tif ∀Ps,t∈G, we havecost(Ps,t′ )≤cost(Ps,t). Theshortest path cost,cost(P′
s,t), is denoted byd(s, t).
The SRCP query is defined over node categories.
Definition II.2. (Category) Given a weighted digraph G = (V, E, w). A category Cis a set of nodes inG, or C⊆V.
Definition II.3. (Regular Expression on Category) The syntax for regular expression on Category is:
R::= ˆC |RR|R “|”R |R“∗”
Here Cˆ is to recognize a category C, i.e., a terminal symbol,
R1R2denotes the concatenation,R1|R2denotes the alterna-tion, andR∗ denotes closure (Kleene star). As usual, we may writeR+ forRR∗.
Definition II.4. (Path Satisfaction) A path Ps,t =
hv1, v2, . . . , vki from s to t is said to satisfy a regular expression R over a set of categories if the concatenation of categories of these nodes spells outR. Such a path is denoted byPs,R,t.
Definition II.5. (Shortest Regular Category-Path (SRCP) / SRCP Query) Given a weighted digraph G = (V, E, w), let
{Ci ⊆V |1 ≤i≤k} be a set of categories of nodes inG, and R be a regular expression over Cis. An SRCP query is represented as a triple
hs, t, Ri
A path Pmin
s,R,t is called an SRCP if it satisfies R, and for every path Ps,R,t inGsatisfying R, we have:
cost(Ps,R,tmin)≤cost(Ps,R,t).
We refer cost(Pmin
s,R,t)asdR(s, t).
Definition II.6. (SRCP problem) An SRCP problem is to find an SRCP for a given SRCP query.
B. Simplification of SRCP Queries
In general, SRCP queries are more difficult to solve than existing category-constrained shortest path queries. The diffi-culty comes from two constructors in the SRCP queries, one is the closure and the other is the alternation. To provide an efficient and practical algorithm to solve SRCP queries, we simplify them by restricting the use of the closure.
Given an SRCP query
hs, t, Ri
whereRis a regular expression, we show that we can simplify the SRCP problem a lot by localizing the global closure. This is based on the following two observations. First, it is usually more practical to consider a path passing a node of category C(i.e., ∗Cˆ ∗, where denotes an arbitrary category) rather than a pathjustcontaining anexactly single nodeof category (i.e.,Cˆ). This would suggest us to treat ∗Cˆ ∗as a primitive. Second, concatenation of ∗ˆC ∗ with a closure will cancel the effect of the closure. This means that the following two SRCP queries,
hs, t, ∗Cˆ ∗R∗i hs, t, R∗ ∗Cˆ ∗i
will have the same effect as the query
hs, t, ∗Cˆ ∗i
It is because the shortest path obtained from the last query should be the shortest path from the first two queries.
Given the above, we will simplify regular expressions to make the closure appear only in the form of ∗ˆC ∗.
Definition II.7. (Simplified Regular Expression (SRE)) The syntax for SREs is:
R::= ∗ˆC ∗ |RR|R “|” R
For simplicity, we use “C” as an abbreviation of “ ∗Cˆ ∗”. In the rest of this paper, we will focus on SRCP queries where simplified regular expressions are considered.
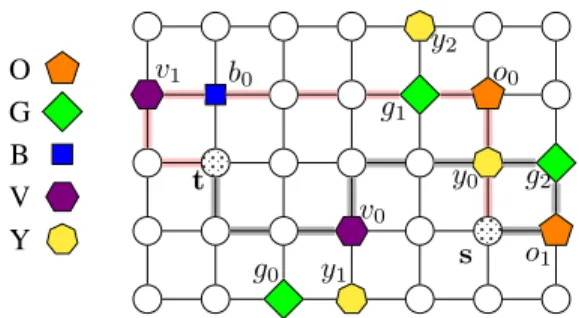
Figure 1 shows an example SRCP query and paths satis-fying the query hs, t,O(GY|B)Vi. The input graph has five categories O, G, B, V, and Y. Nodes in the same category have the same shape and color. Because of alternations in the query, it is possible to have many optimal paths Pmin
s,R,t that have the same optimal costdR(s, t). Also note that there is no requirement that two nodes in two different categories must be directly connected. For example, the optimal path
hs, o1, g2, y0, . . . , v0, . . . , tispells out the constraint “OGYV”, however the nodey0inYconnects to the nodev0inVvia two other nodes, althoughYandVare contiguous in the constraint.
O G B V Y
v1 b0
t
g0
v0
y1
y2
g1
o0
y0
s
g2
o1
Fig. 1: An SRCP query examplehs, t,O(GY|B)Vi. All edges have the same weight of 1. Two of the SRCPs are shaded in grey and pink.dR(s, t) = 9
C. Expressiveness
We show that SRCP queries are powerful enough to express many interesting category-constrained shortest path queries including those with partial or total order constraints.
1) Generalized Shortest Path (GSP) Queries: This query is to find the shortest path from a starting point to a destination point, passing at least one point from each of a set of specified categories in a specified order [5]. A GSP is expressed in our SRCP query as follows.
hs, t,C1C2. . .Cki
where s and t are the starting point and destination point, respectively.
2) Optimal Sequenced Route (OSR) Queries: An OSR query is to find the shortest path starting from a given point and passing through a number of categories in a particular order [3]. This query is different from the GSP query in the sense that the destination is not a point but a category. To express this query in our SRCP query, we create an artificial destination nodet′ in the input graph, and add edges with weight 0 from nodes in the last category of the order constraints tot′. The SRCP query is then as follows.
hs, t′,C1C2. . .Cki
3) Trip Planning Queries/Generalized Traveling Sales-man Path Problem Queries (TPQ/GTSPP): A trip planning query [1] or generalized traveling salesman path problem query [2] is to find the shortest path from a starting point to a destination point that passes through at least one point from each of a set of categories (there is no specific order specified in the query). A TPQ/GTSPP query with a set ofk
categories is written in our SRCP query as follows.
hs, t, R1|R2|. . .|Rk!i
where Ris (i = 1. . . k!) are permutations of the set
{C1,C2, . . . ,Ck}. For example, R1 is C1C2. . .Ck, R2 is C2C1. . .Ck, and so on.
Regular-Expression-Constrained Shortest Path Queries [6]
General SRCP Queries (this paper)
SRCP Queries with SREs (this paper)
ORQ with Arbitrary Order Constraints [4]
No Order Total Order
(TPQ [1], GTSPP [2]) (OSR [3], GSP [5])
Fig. 2: The relationship between SRCP queries and existing queries
However, here users can specify partial order constraints between some specific categories of the set, e.g. a gas station must be visited before a restaurant, while other categories can be visited in an arbitrary order. Such order constraints are expressed in a visit order graph, in which each node is a category, an edge from a categoryCi to a categoryCjdenotes that Ci must be visited beforeCj.
To express the optimal route queries with arbitrary order constraints in our SRCP query, there are two things needed to be done. First, we need generate total order constraints from the visit order graph, then put them together in the form of SRCP queries by using alternation operators. A simple way to generate the total order constraints is first enumerating all permutations of the set of categories, and then filtering out permutations that do not satisfy constraints in the visit order graph. Second, we need create an artificial destination node
t′ for the SRCP query, which is done by adding edges with weight0 from nodes in all categories in the set of categories tot′. The SRCP query is finally as follows.
hs, t′, R1|R2| . . .|Rli
where Ris (i = 1. . . l) are total order constraints satisfying the visit order graph.
In summary, Figure 2 shows the relationships between our SRCP queries and other queries. The general SRCP query is a subset of the regular-expression-constrained shortest path query [6] in which its regular expression is defined over node labels. A practical subset of the general SRCP queries, whose constraints are simplified regular expressions, is considered in this paper. Although it is limited but covers all existing important problems such as queries with arbitrary order, total order, or no order constraints.
III. SRCP QUERYALGORITHM
A naive approach for answering the SRCP query(s, t, R)is considering it as a combination of existing queries with total order constraints. To do that, we first generate all total order constraints Ri of the input SRE R. For example, consider an SRE “B(C|S)”, we generate two equivalent constraints
R1 = “BC” and R2 =“BS”. Then we evaluate sub-queries
hs, t, Rii, e.g.hs, t,BSi,hs, t,BCi, independently by efficient algorithms for total order constraints (e.g. algorithms for optimal sequenced route [3] or generalized shortest path [5]).
Finally we take the minimum cost from results of each sub-queries. This approach is straightforward but inefficient due to many redundant computations between the evaluations of sub-queries, e.g. two sub-queries in the above example would share a computation for paths fromsto the categoryB. Moreover, computations from the categoryBto the categoryCandScan be overlapped in terms of visited edges/nodes.
In this section, we propose a dynamic programming solution to solve the SRCP problem in a more efficient way, in which we reduce the SRCP problem to a series of single source shortest path searches.
A. SREs as Directed Acyclic Graphs
It is well known that a regular expression can be expressed by a nondeterministic finite state automaton withǫ-transitions (NFA-ǫ) [9]. However, the use ofǫ-transitions is not necessary due to the absence of closures in SREs of SRCP queries. Hence, we directly transform an SRE to an NFA without ǫ -transitions. This NFA is a directed acyclic graph (DAG) GR that represents the structure of SREs in SRCP queries. Nodes ofGR are object identifiers (OIDs) that are integers uniquely identifying a node, and edges ofGRare labeled by categories inR.
The graphGRis simply constructed by a recursive function on the structures of SREs. Algorithm 1 is to generate a DAG graph for an given SRE. Given an SRE R, the recursive function ParseSRE computes a triple hsc,GR,ski where
sc and sk are the source and sink node in the graph GR,
respectively. For the terminal caseR=C(see Alg. 1, lines 2-6), we create a singleton graphGC containing only one edge
dlabeled by the categoryC. The source and sink node ofGC are respectively the source and target node ofd(see Fig. 3a for an illustration ofGC). For the concatenation caseR=R1R2 (see Alg. 1, lines 7-13), the graph GR is constructed from two graphs GR1 of R1 andGR2 of R2 by merging the sink node ofGR1 with the source node ofGR2 (see Fig. 3b for an example). For the alternation case R =R1|R2 (see Alg. 1, lines 14-22), we create the graph GR from GR1 and GR2 by merging the source node ofGR1 with the source node of
GR2, and the sink node of GR1 with the sink node of GR2 (see Fig. 3c for an example). The generated graph GR is a DAG with one source node and one sink node.
To present the semantics of the whole queryQ=hs, t, Ri, we introduce a query graph GQ = (VQ, EQ) that is con-structed from the graph GR by attaching an in-coming edge labeled by {s} to the source node of GR, and an out-going edge labeled by{t} to the sink node of GR. Figure 4 shows a query graph of the query hs, t,O(GY|B)Vi, in which two sets{s} and{t}are called dummy categories (superscripts of edge labels will be explained later in the Sect. III-B).
B. Dynamic Programming Formulation
Algorithm 1: ParseSRE(R)
input : A simplified regular expression R
output : A triplehsc, GR, ski
1: switchR do
2: caseC
3: u←newVertex(); 4: v←new Vertex();
5: GC←new DAG({u,v},{(u,C,v)});
6: returnhu, GC, vi
7: caseR1R2
8: hsc1, GR1, sk1i ←ParseSRE(R1);
9: hsc2, GR2, sk2i ←ParseSRE(R2);
10: w←newVertex();
11: replace sk1∈GR1 andsr2∈GR2 byw; /* merge two graphs */
12: GR←newDAG(V(GR1)∪V(GR2), E(GR1)∪
E(GR2));
13: returnhsc1, GR, sk2i
14: caseR1|R2
15: hsc1, GR1, sk1i ←ParseSRE(R1);
16: hsc2, GR2, sk2i ←ParseSRE(R2);
17: sc12←newVertex();
18: sk12←newVertex();
19: replace sc1∈GR1 andsc2∈GR2 by sc12;
20: replace sk1∈GR
1 andsk2∈GR2 bysk12;
/* merge two graphs */
21: GR←newDAG(V(GR1)∪V(GR2), E(GR1)∪
E(GR2));
22: returnhsc12, GR, sk12i
23: endsw
table corresponds to a category on an edge of the graph
GQ. Therefore, the table X has |EQ| rows, and g columns where g is the maximum size of categories in the query Q. “X[i, j]” is the value for the j-th node in the category at the row i. For simplicity, we add superscripts to categories in the query to denote their row indices in the table. For example, with the user-defined query hs, t,O(GY|B)Vi, we havehs0, t6,O1(G2Y3|B4)V5i.
The DP table X is computed according to a topological sort of the query graphGQ as follows. For each nodeuin the topological sort, we generate acomputation step,inu→outu, where
inu ={r|(v, u)∈EQ, Cr←l(v, u)}
outu ={r|(u, w)∈EQ, Cr←l(u, w)},
computing values of the rows in the listoutuby using values in the rows in the list inu, in which l(u, v) is a function to get a label of an edge(u, v)inGQ. Computation steps form a dynamic programing formulation for the SRCP problem. Following is the computing formulation of the computation step inu→outu.
u v
GC:
C
(a) Singleton graphGC
u1 v1
u2 v2
C1
C2
u1 w v2
C1 C2
GR1 :
GR2 :
GR:
(b) Concatenation case:R=R1R2 (e.g.R1=C1,R2=C2)
u1 v1
u2 v2
C1
C2
w1 w2
C1
C2
GR1 :
GR2 :
GR:
(c) Alternation case:R=R1|R2 (e.g.R1=C1,R2=C2)
Fig. 3: Query graph constructors
0 1 2
3
4 5 6
{s}0 O1 G
2
B4 Y3
V5 {t}6
Fig. 4: A query graph of the queryhs, t,O(GY|B)Vi. Integers in nodes are OIDs. Superscripts of categories are equivalent row indices in the DP table. The subgraph from the node
1 to the node 5 is a DAG graph corresponding to the SRE O(GY|B)V
X[i, j] i∈outu
=
0 Ifi= 0
min r∈inu
{ min
0≤l<|Cr|{
X[r, l] +d(cr,l, ci,j)}} Ifi >0
where,Cr
is the category corresponding to ther-th row in the DP table X,ci,j is the j-th node in the categoryCi.
Lemma III.1. Value X[i, j] in the DP table represents the optimal cost of the SRCP of the query hs, ci,j, Rii whereRi is the SRE corresponding to a subgraph of GQ that includes all paths from the node just after the source node of GQ to the source node of the edge labeledCi.
For example, consider the queryhs0, t6,O1(G2Y3|B4)V5i, its query graph is shown in Fig. 4. The value X[3,1] will represent the optimal cost of the SRCP of the queryhs, y1, R3i in which R3 = O1G2 corresponding to the subgraph having edges from the node1(the node just after the source node of
GQ) to the node3(the source node of the edgeY3).
For the base case, where k = 1, then this claim is trivially true, becauseX[0,0]is the optimal cost for the query
hs,c0,0, R0i=hs, s,{}iwhich hasdR(s, s) = 0.
For the induction step,k >1. Letube the node inGQ that generates thek-th computation step. For a set of nodesVuthat are before the node u in the topological sort of GQ, let Eu be a set of edges related to nodes in Vu, and ps be a set of row indices of categories on the edges in Eu. Our induction hypothesis assumes that this claim holds true for all values
X[i,•], i∈ ps. Let consider the (k+ 1)-th computation step generated by the nodev inGQ, that isinv→outv, in which
invandoutvis the set of row indices of all in-coming and out-going edges of the nodev, respectively. It is clear thatinv⊆
ps. Since eachci,jis a member of categoryCi,i∈outv, j= 0. . .(|Ci| −1), it suffices to find the shortest path cost from nodes cr,l in categories Cr (r∈inv,0≤l <|Cr|) toci,j. It follows from our induction hypothesis that the value ofX[i, j]
is computed by min r∈inv
{ min
0≤l<|Cr
|{X[r, l] +
d(cr,l, ci,j)}}.
Corollary III.2. Let m be the row index of the dummy category {t}. Value X[m,0]represents the cost of the SRCP of the query hs, t, Ri.
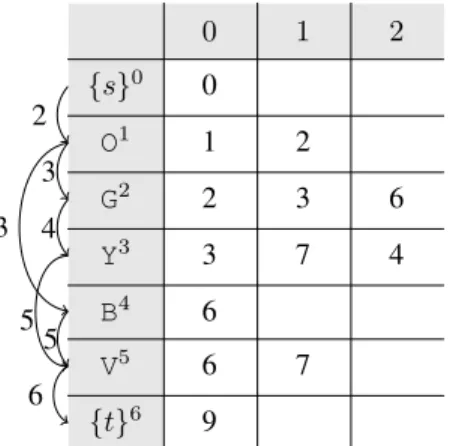
Figure 5 shows a table containing costs during the com-putation of the queryhs0, t6,O1(G2Y3|B4)V5i. The order of computation steps is as follows.
1st step: [] →[0]
2nd step: [0] →[1]
3rd step: [1] →[2,4]
4th step: [2] →[3]
5th step: [3,4] →[5]
6th step: [5] →[6]
7th step: [6] →[]
The optimal costdR(s, t) = 9of the query is stored at the last row (its row index is 6 that is the index of the dummy category{t}) of the table. Note that the first step is actually to initialize the value ofX[0,0], and the last step does nothing.
C. Single Source Shortest Path (SSSP) Search
A computation step “xs → ys” is to compute values in rows in the listysby using rows inxs. LetUxsbe a union of categories corresponding to rows in xsandUys be a union of categories corresponding to rows in ys, then the step “xs→ ys” is equivalent to computing values for the nodes in category
Uys from values of the nodes in category Uxs. This can be done by using a many-to-many shortest path search from the nodes in Uxs to the nodes in Uys. However, such a many-to-many search leads to many redundant computations due to repeatedly visiting the input graph. By creating a super-node
s′ and edges froms′ to the nodesuinUxswith weights being values of u in the DP table [5], we can efficiently compute values for the nodes in Uys by using a single shortest path search froms′ until all nodes in Uys are settled (Assume that we use Dijkstra algorithm).
Theorem III.3. Given a weighted digraph G = (V, E, w)
and an SRCP query Q = hs, t, Ri. Let GQ = (VQ, EQ)
0 1 2
{s}0 0
O1 1 2
G2 2 3 6
Y3 3 7 4
B4 6
V5 6 7
{t}6 9
2
3
3 4
5 5
6
Fig. 5: A table of optimal costs for the query in Fig. 1. The first column contains names of categories. The first row contains indices of nodes in a category. Each row contains optimal costs froms to a node in a category via some other categories according to the SRE. Curved arrows on the left indicate computation steps and its orders.
be the query graph of Q and Tsssp be the complexity of a single source shortest path search, the cost of our algorithm isO(|VQ|Tsssp), and the space complexity of the algorithm is
O(|EQ|).
Corollary III.4. Given a weighted digraph G = (V, E, w)
and an SRCP queryQ=hs, t, Ri. LetGQ = (VQ, EQ)be the query graph ofQ. When a Dijkstra algorithm with a Fibonacci heap is used for SSSP searches [10], our algorithm answers
Qin the time complexity ofO(|VQ|(|E|+|V|log|V|)).
One advantage of this approach is that it is independent of the underlying SSSP search. Thus, we can use any fast SSSP algorithm to implement, such as Contraction Hierarchies technique [7], [5], Delta-Stepping [11], PHASE [12], etc. This is useful because we can apply different efficient fast SSSP algorithms for different kinds of graphs (road networks, social networks, biological networks, etc.)
IV. OPTIMIZATIONS
Although the dynamic programming formulation can help solve the SRCP problem, there is a need in optimizing the SRCP query algorithm. First, the number of computation steps (|VQ|) depends on user-defined queries. For example, two queries, hs, t,(OGYV|OBV)i andhs, t,O(GY|B)Vi, have the same meaning, but the former needs 6 computation steps and the latter needs only 5. Second, consider the Trip Planning Query that is to find the shortest path going through at least one point in each category of a given set of categories C={C1,C2, . . . ,Ck}. It can be presented in SRCP query as
Optimization is to reduce the size of the query graph GQ. In particular, there are two measures for the size of the query graph: the number of nodes and the number of edges. The number of nodes affects the time complexity and the number of edges affects the space complexity that is the size of the dynamic programming table. Here, we focus on the problem of optimizing the time complexity, therefore the problem can be defined as finding a graph with the minimum number of nodes that generates exactly the same total order constraints as a given query graph.
The query graph is a subclass of non-deterministic finite state automatons (NFA) [9]. It is well known that NFA minimization is computationally hard, and cannot in general be solved in polynomial time. There exists a well-known algorithm for minimizing NFAs [9]. The algorithm computes a minimal equivalent deterministic finite automaton (DFA) with respect to the number of nodes, and consists of two steps: determinization and minimization. The determinization step is to compute a DFA from an NFA, then the DFA is minimized by the minimization step to get a minimal DFA.
Str¨om [13] has proposed two simplified algorithms for the two steps determinization and minimization in the case of word graphs that represent a set of hypotheses in speed recognition system. A word graph is a DAG with exactly one source node and one sink node. In this section we apply these algorithms to optimize the query graph which has a similar structure to word graphs.
A. Forward Optimization (Determinization)
A deterministic finite state automaton (DFA) has a property that, given a sequence of categories, there is at most one path in the DFA that generates it. The key to a determinization algorithm is identifying the correspondence between a set of nodes in the original graph and a node in its DFA graph. This leads to an exponential computation because there are2N
sets of nodes in a graph ofN nodes. However, the algorithm can be simplified in the case of the query graph that is a DAG with one source node and one sink node.
The idea of a forward optimization is scanning the query graph GQ from its source node to its sink node, and grouping nodes that come from the same node with the same categories [13]. LetDGQ be a deterministic query graph that is the result of the forward optimization, a node in DGQ is correspondent to a set of nodes in GQ. Figure 6 describes an example of the forward optimization for the query
hs, t,C1C4C6C9|C1C4C7C9|C1C5C7C9|C2C8C9|C3C8C9i. Initially, the graphDGQcontains only one node created from the source node 0 of GQ. Because there is only one edge going out from the node 0 of GQ, a new node in DGQ is also correspondent to only one node in GQ (node 1). In the next step, since there are three out-going edges of the node 1
in GQ with the same category C1, we can group their target nodes into one set {2,3,4} and create a new equivalent node in DGQ. Two nodes 7 and 9 in GQ are both coming from nodes in the same set {2,3,4} with the same categories C4,
0 1 4
3 2 5 6 7 8 9 10 11 12 13 14 15 16
{
s
}
C
1C
1C
1C
2C
3C
4C
4C
5C
6C
7C
7C
8C
8C
9C
9C
9C
9C
9{
t
}
(a) A query graph GQ of the query
hs,t,C1C4C6C9|C1C4C7C9|C1C5C7C9|C2C8C9|C3C8C9i.
Nodes in the same rectangular are needed to be grouped
0 1 2
5 6 11 7 10 8 12 13 14 15 16
{
s
}
C
1C
2C
3C
5C
4C
7C
6C
7C
8C
8C
9C
9C
9C
9C
9{
t
}
(b) A deterministic query graphDGQofGQ
Fig. 6: Forward optimization.
thus we also group them to create a new node inDGQ, This procedure is performed until reaching the sink node of GQ.
B. Backward Optimization (Minimization)
This optimization is applied to the deterministic graph that is the result of the forward optimization. The idea of a backward optimization is that if there are multiple nodes going to the same node with the samesetof categories, then we group them into one node. Because the deterministic query graph is a DAG in which edges go from the source node towards the sink node, we will process nodes in the reverse order from the sink node util reaching the source node. We call this processbackward optimization. This process is the same as minimizing a DFA because it merges any pair of nodes that generate exactly the same sequence of categories.
Figure 7 describes a process of the backward optimization. We initialize the minimal deterministic query graph M DGQ with the sink node in the input deterministic query graph
0 1 2
5
6 11
7 10
8
12
13
14
15 16
{
s
}
C
1C
2C
3C
5C
4C
7C
6C
7C
8C
8C
9C
9C
9C
9C
9{
t
}
(a) A deterministic query graphDGQ. Nodes in the same rectangular
are needed to be grouped
0 1 2
5 11
7
8 15 16
{
s
}
C
1C
2C
5C
4C
7C
7C
8C
9{
t
}
C3
C6
(b) Minimal deterministic query graph M DGQofDGQ
Fig. 7: Backward optimization
and the nodes that they go to. To store such information, for each node, we maintain a set of tuples of an out-going edge’s label and an equivalent target node. If there are multiple nodes having the same set, then we group them to create a new node in the graph M DGQ. For example in Fig. 7, because five nodes8,9,10,12,13,14inM DQ (see Fig. 7a) go to the same node15with the same edge labelC9, so we group them and create an equivalent node 8 in the graph M DGQ (see Fig. 7b). Note that, although two nodes7and11inDGQ go to nodes in the same set{8,9,10,12,13,14}, we do not group them. This is because the node 7 has two edges to nodes in
{8,9,10,12,13,14}, while the node11has only one edge to nodes in{8,9,10,12,13,14}.
C. Optimization of the DP Table
For our approach, the number of rows in the DP table is equal to the number of edges in the query graphGQ. Although the optimization of the number of nodes inGQ also causes a decrease of the number of edges, this decrease is not remark-able. Moreover, because the number of elements in each row of the table is equal to the number of nodes in the equivalent category, the size of the DP table becomes large when the query contains a ”long” total order constraints, leading to out-of-memory errors. Therefore we need to efficiently manage the DP table.
One solution to managing the DP table is dynamically creating it. As discussed earlier, the DP table is constructed according to a topological sort of the query graph of a query. When considering a node in that order, in-coming edges are
used to compute values for rows corresponding to out-going edges, and never used again. Thus, after each computation step, we need not store rows corresponding to in-coming edges.
D. Optimization of the Query Structure
Although two forward and backward optimizations result in a minimal query graph GQ in terms of the number of nodes, for some user-defined queries, we can get a smaller graphGQ by preprocessing the SREs in the user-defined queries.
Consider SRCP queries in the following form
hs, t, R1R2R3|R2i
where R1, R2, R3 are arbitrary SREs. They have the same effect as the query
hs, t, R2i
Therefore, for this kind of queries, we can eliminate all SREs that contain another SREs. This can be generalized for SRCP queries having more alternatives.
V. IMPLEMENTATION ANDEVALUATION
We implemented a framework1to answer the SRCP queries.
The overview of our framework is showed in the Fig. 8. First, it takes an SRCP query as input, parses it to get a query graph, then optimizes the query graph by two steps “determinization” and “minimization”. Next, it will generate a sequence of computation steps, in which each computation step is executed by a single source shortest path search. For simplicity, we just compute the optimal cost for the optimal path satisfying the query. However, one can extract the optimal path by keeping traces of computation steps.
For the implementation of a single source shortest path, we used a fast algorithm proposed by Rice [5], which has been engineering based on the speed-up technique called Con-traction Hierarchies. ConCon-traction Hierarchies (CH) technique currently is one of the fastest speed-up technique for shortest path problem on road networks [14]. Its idea is preprocessing a graph by augmenting it with shortcuts so that shortest path costs are preserved. Shortcuts are then intensively used by a bidirectional Dijkstra algorithm to speed up the shortest path search on the augmented graph.
A. Environment
All our experiments were ran on a Macbook Pro machine which has a 2.6 GHz Intel Core i5, 8 GB 1600 MHz DDR3 memory, clang-503.0.40 (based on LLVM 3.4svn). Programs were compiled with optimization level 3. We used a library of contraction hierarchies written by Robert Geisberger2 in C++
to create and access an augmented graph.
Experiments were performed with a graph of the Full USA road network, having 23,947,347 nodes and 58,333,344
edges. We borrowed the graph from the benchmarks of the
User-defined Query
Parser
Determinization Minimization
CSs Generation CSs Execution Graph
Optimal Cost SRCP Query System
Fig. 8: The overview of our framework
9th DIMACS implementation challenge 3. It took about 25
minutes to create an augmented graph using the CH technique (this graph will be used as a common input graph for programs in our experiments)
The following programs are implemented and used in our experiments to compare results of discussed algorithms.
• gsp: the algorithm proposed by Rice [5] to answer the Generalized Shortest Path Query that uses total order constraints hs, t,C1C2. . .Cki. We implemented the core of this algorithm (without some heuristic technique).
• perm: a naive algorithm, which was mentioned in the beginning of the Sect. III, to answer the SRCP query by evaluating sub-queries for all total order constraints, then taking the minimal cost from the sub-queries. Sub-queries are evaluated by thegspalgorithm.
• srcp-noopt: our algorithm for the SRCP query without
optimizations.
• srcp-opt: our algorithm for the SRCP query with
op-timizations. Two optimizations were implemented: the forward and the backward. To store a set of nodes, we used a standard class std::set which supports equality comparison. We used a class std::unordered map as a hash table to store sets of nodes, which allows for fast access to the sets of nodes to determine their existing and elements. The boost graph library4is used to implement the optimizations.
Categories used in our queries are generated randomly and have the same number of nodes.
B. Results
1) Influence of the Optimizations: We measure the perfor-mance of our algorithm for the trip planning queries which are expensive queries. A Trip Planning Query (TPQ) with k
categories is written in the SRCP queries as follows.
hs, t, R1|R2|. . . |Rk!i
where Ris are permutations of the set {C1,C2, . . . ,Ck},i=
1. . . k!. For example, R1 is C1C2. . .Ck, R2 is C2C1. . .Ck, and so on.
39th DIMACS implementation challenge: shortest paths. 2006.
http://www.dis.uniroma1.it/challenge9/.
4http://www.boost.org/doc/libs/1 55 0/libs/graph/doc/
100 101 102 103
100 101 102 103 104 105
Query Time (second)
The Numbers of Nodes in Categories (g) perm (720 steps)
srcp-noopt (482 steps) srcp-opt (32 steps)
(a) TPQ/GTSPP queries. Vary the size of categories (g), fix the number of categories (k= 5)
0 10 20 30 40 50 60 70 80 90
1 2 3 4 5
Query Time (second)
The Number of Categories (k) perm
srcp-noopt srcp-opt
(b) TPQ/GTSPP queries. Vary the number of categories (k), fix the size of categories (g= 10,000)
First, we fix the number of categories being 5, and then change the size of categories. The naive solution that generates all permutations of categories requires720 computation steps ((5 + 1)∗5!). Without optimizations, our algorithm generates
482computation steps which is nearly half of that of the naive solution. By using optimizations, the number of computation steps reduces to32(25) that is more practical. Performance of algorithms is represented in the Fig. 9a. It shows that the srcp-optalgorithm is quite scalable when the size of categories is increased.
0 1 2 3 4 5 6 7 8 9 10
Q1 Q2 Q3 Q4 Q5
Query Time (second)
Queries perm
srcp-opt
Fig. 10: Queries with multiple options (k= 8, g= 10,000)
TABLE I: The number of computation steps in each query
Q1 Q2 Q3 Q4 Q5 perm 9 16 28 48 80 srcp-opt 9 8 7 6 5
2) Influence of the Alternation Operators: To see the im-pact of alternation operators (|) for a given query on the performance of our optimal algorithm, we do experiments with queries which differ in the number of alternation operators, while the number of categories is the same. Starting with a query without alternatives, each time we insert one “|” operator to create a new query. In particular, we use the following queries.
Q1 =hs, t,C1C2C3C4C5C6C7C8i
Q2 =hs, t,(C1|C2)C3C4C5C6C7C8i
Q3 =hs, t,(C1|C2)(C3|C4)C5C6C7C8i
Q4 =hs, t,(C1|C2)(C3|C4)(C5|C6)C7C8i
Q5 =hs, t,(C1|C2)(C3|C4)(C5|C6)(C7|C8)i
Figure 10 shows the result. It is interesting that when there are more options in the SRCP query, our algorithm becomes faster. Looking the Table I that shows the number of com-putation steps for each query, we see that the reason of such good performance is that the number of computation steps is reduced, leading to a decrease of the running time of our algorithm. Meanwhile, if we use thepermalgorithm, then the number of computation steps will be dramatically increased because there are many total order constraints generated. This result also shows that our algorithm can reduce a large amount of redundant computation steps when alternation operators appear in the query.
3) Overhead of Optimizations: First, we measure the per-formance of our algorithm when answering the query GSP. We compare it to the algorithm proposed by Rice [5]. As can be seen in the Fig. 11, two algorithms have the same performance when the number of categories is increased. This is easy to understand because, for this query, our algorithm leads to the same dynamic programing table as that of gsp
0 0.5 1 1.5 2 2.5 3
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Query Time (second)
The Number of Categories (k) gsp
srcp-opt
Fig. 11: GSP queries (g= 10,000)
TABLE II: Performance of optimizations
1 2 3 4 5 6
forward (ms) 0.026 0.033 0.069 0.290 2.566 53.697 backward (ms) 0.018 0.034 0.084 0.302 1.580 10.872
algorithm. Moreover, there is no improvement on the structure of the query when applying optimizations, thus the overhead is very small.
However, for the trip planning queries, the overhead of optimizations, in particular, the overhead of the forward op-timization, is expensive. Table II shows the running times of the forward and backward optimizations when the number of categories (k) is changed from1to6. With smallk(1,2,3,4), the backward optimization takes less time than the forward optimization. Nevertheless, the forward optimization is more expensive with larger k (5,6). This is because, the forward optimization takes an exponential time complexity, while the backward optimization takes a linearithmic time complexity. Furthermore, both optimizations highly depend on the way of storing sets of nodes during their computations. This effects the performance of determining whether a set already exists or not.
VI. RELATEDWORK
The category-constrained shortest path problem is a variant of regular-language-constrained shortest path queries in which constraints are on a set of nodes in a graph instead of individual nodes/edges. There are many solutions proposed to answer such queries. Each solution is for a specific kind of constraints over categories.
have not been visited yet. The second one is the minimum distance algorithm, a novel greedy algorithm, which results a much better approximation bound. The algorithm chooses a set of nodes, one node per one category in the query. These nodes are chose so that the total distance from the start node to it and from it to the end node is the minimum among nodes in the same categories. The algorithm then create a path by following these nodes in nearest neighbor order. Rice et al. [2] proposed an exact solution for the Generalizes Traveling Salesman Path Problem Query (GTSPP) that is similar to TPQ. The algorithm is building a product graph of the original graph
G = (V, E) and a covering graph built on the power set of the query’s categories. Finding the answer of the GTSPP query is finding the shortest path in the product graph. The time complexity is 2k(|E| +|V|k +|V|log|V|)
, in which
k is the number of categories in the query. The algorithm is then improved by incorporating the graph preprocessing technique called Contraction Hierarchies (CH) [7], resulting in the time complexity of O(2k(m′+|V|k), in whichm′ is
the number of edges of the preprocessed graph. It is noted that the improved algorithm is slightly different from the orignal algorithm, in which it executes a series of sweeping phases according to levels of an abstraction of the product graph, and highly depends on the CH technique.
In parallel to Li et al.’s work [1], Sharifzadeh et al [3] proposed the optimal sequenced route query (OSR) that is similar to TPQ but imposes a total order constraints over cat-egories. In other words, OSR query is to find the shortest path starting from a given point and passing through a number of categories in a particular order. They proposed two algorithms to operate on the Euclidean distance. The first one is LORD, a light threshold-based iterative algorithm. First, LORD uses a greedy search to find an threshold (upper-bound) for the cost of the optimal path. The greedy search is a successive nearest neighbor search from the starting node to the last category. Then, the LORD finds the optimal path in the reverse order, from the last category to the starting node. During the finding, it updates the threshold value and uses it to prune nodes that cannot belong to the optimal path. The second algorithm is R-LORD, an extension of the LORD, that uses R-tree to efficiently examine the threshold values. However, both algorithms are impractical to road networks where nearest neighbor searches are very expensive. Thus, another algorithm, progressive neighbor exploration (PNE), has been proposed in the paper. The idea of the PNE is incrementally create the set of candidate paths. At each step it needs two nearest neighbor searches: one is to expand the current best candidate path, the other is to refine that path by replacing the last node in the path by a new node.
Sharifzadeh et al. [15] introduced a pre-processing approach for the OSR query by using additively weighted Voronoi diagrams. This approach is efficient and practical compared with R-LORD algorithm, however, one of the disadvantages is that it is not flexible when requiring fixed sequences among categories. Rice et al. [5] proposed another approach using Contraction Hierarchies technique and dynamic programming
for the Generalized Shortest Path (GSP) query that is the same as the OSR query but having only one destination point. Its advantage is that it can be apply for any possible set of categories in a query. Our work is inspired by the idea of a dynamic programming formulation from Rice et al.’s work, and we extend their algorithm in two aspects. First, we allow multiple categories involved in a computation steps. Second, we introduce “jumping” computations in the DP table that compute an arbitrary row from an other arbitrary row in the table, allowing us freely describe computation steps guided by a directed acyclic graph representation.
Being close to our SRCP query is the optimal route queries with arbitrary order constraints proposed by Li et al. [4]. This query considers partial order constraints over categories, which are described by a visit order graph. Two algorithms have been proposed namely Backward search and Forward search. The backward search algorithm computes the optimal paths in reverse manner similar to R-LORD algorithm [3]. However, instead of loading nodes belonging to the last category, the backward search retrieves the set of candidate nodes that may be part of the optimal path, which belong to any categories contained in the visit order graph. The forward search is similar to a greedy algorithm. It also use the backward search algorithm for backtracking process, eliminating some nodes that cannot be a part of the optimal path. Both algorithms have the time complexity of O(N2·2k), in which k is the number of categories in the visit order graph and N is the total number of nodes in the data set (road network or spatial database).
VII. CONCLUSIONS ANDFUTUREWORK
In this paper, we have introduced the general SRCP query for finding the optimal path constrained by categories. We have found a reasonable subset of the general SRCP queries that uses simplified regular expressions as constraints. Even though this subset is limited, it covers all of the existing category-constrained shortest path queries and has efficient implementation. We have proposed a dynamic programming formulation to solve the subset of SRCP queries in which it is reduced to a sequence of single source shortest path searches on the input graph. This result is important because we can use any fast single source shortest path search even with preprocessing to speed up the query. By exploiting a directed acyclic graph representation of a query, we can easily derive an efficient algorithm for answering the query.
(visiting a node at most once); it is interesting but very difficult to solve [6], [16].
ACKNOWLEDGMENT
The authors wish to thank Akimasa Morihata for fruitful discussion of earlier work in this paper. We thank Kiminori Matsuzaki for suggesting the use of a directed acyclic graph in analyzing queries. Also, thanks are to IPL and POPP members for their useful comments.
REFERENCES
[1] F. Li, D. Cheng, M. Hadjieleftheriou, G. Kollios, and S.-H. Teng, “On trip planning queries in spatial databases,” inProceedings of the 9th International Conference on Advances in Spatial and Temporal Databases, ser. SSTD’05, 2005, pp. 273–290.
[2] M. N. Rice and V. J. Tsotras, “Exact graph search algorithms for generalized traveling salesman path problems,” inProceedings of the 11th International Conference on Experimental Algorithms, ser. SEA’12, 2012, pp. 344–355.
[3] M. Sharifzadeh, M. Kolahdouzan, and C. Shahabi, “The optimal se-quenced route query,”The VLDB Journal, vol. 17, no. 4, pp. 765–787, Jul. 2008.
[4] J. Li, Y. Yang, and N. Mamoulis, “Optimal route queries with arbitrary order constraints,”IEEE Trans. on Knowl. and Data Eng., vol. 25, no. 5, pp. 1097–1110, May 2013.
[5] M. N. Rice and V. J. Tsotras, “Engineering generalized shortest path queries,” inProceedings of the 2013 IEEE International Conference on Data Engineering (ICDE 2013), ser. ICDE ’13, 2013, pp. 949–960. [6] C. Barrett, R. Jacob, and M. Marathe, “Formal-language-constrained
path problems,”SIAM J. Comput., vol. 30, no. 3, pp. 809–837, May 2000.
[7] R. Geisberger, P. Sanders, D. Schultes, and D. Delling, “Contraction hierarchies: Faster and simpler hierarchical routing in road networks,” in Proceedings of the 7th International Conference on Experimental Algorithms, ser. WEA’08, 2008, pp. 319–333.
[8] J. Maue, P. Sanders, and D. Matijevic, “Goal-directed shortest-path queries using precomputed cluster distances,” J. Exp. Algorithmics, vol. 14, pp. 2:3.2–2:3.27, Jan. 2010.
[9] J. E. Hopcroft, R. Motwani, and J. D. Ullman,Introduction To Automata Theory, Languages, And Computation, 2nd ed. Boston, MA, USA: Addison-Wesley Longman Publishing Co., Inc., 2001.
[10] M. L. Fredman and R. E. Tarjan, “Fibonacci heaps and their uses in improved network optimization algorithms,”J. ACM, vol. 34, no. 3, pp. 596–615, Jul. 1987.
[11] U. Meyer and P. Sanders, “Delta-stepping: A parallel single source shortest path algorithm,” in Proceedings of the 6th Annual European Symposium on Algorithms, ser. ESA ’98, 1998, pp. 393–404. [12] D. Delling, A. V. Goldberg, A. Nowatzyk, and R. F. Werneck, “Phast:
Hardware-accelerated shortest path trees,” inProceedings of the 2011 IEEE International Parallel & Distributed Processing Symposium, ser. IPDPS ’11, 2011, pp. 921–931.
[13] N. Str¨om, “Automatic continuous speech recognition with rapid speaker adaptation for human/machine interaction,” Ph.D. dissertation, KTH, Stockholm, 1997.
[14] H. Bast, D. Delling, A. V. Goldberg, M. Muller-Hannemann, T. Pajor, P. Sanders, D. Wagner, and R. F. Werneck, “Route planning in trans-portation networks,” Tech. Rep. MSR-TR-2014-4, 2014.
[15] M. Sharifzadeh and C. Shahabi, “Processing optimal sequenced route queries using voronoi diagrams,” Geoinformatica, vol. 12, no. 4, pp. 411–433, Dec. 2008.